Your model works. How do you know it works well enough?
Every team that ships an LLM application eventually hits the same wall. The demo is impressive. The pilot users are happy. Then someone asks: how do we know this is good enough for production? And nobody has a rigorous answer.
Accuracy is not enough. A model can score 92% on a benchmark and still hallucinate on the 8% that matters most -- the edge cases, the ambiguous inputs, the queries that carry legal or financial risk. The gap between "works in testing" and "safe to deploy" is where most AI programs stall.
Evaluation is the discipline that closes that gap.
Not just metrics. A systematic practice: how to find errors before users do, how to build evaluators that catch regressions, how to align AI quality with business outcomes, and how to monitor it all in production without drowning in dashboards.
8 modules covering systematic error analysis, automated evaluation pipelines, LLM-as-judge patterns, human review workflows, production monitoring, and cost optimization. Framework-agnostic -- works with Claude, GPT, Gemini, Llama, or any model you deploy.
The capstone project is a complete evaluation system you can deploy to your own stack.
AI Evals: From Theory to Production
A practical framework for evaluating LLM applications. Go beyond simple accuracy metrics to build robust, reliable, and business-aligned AI systems.
Learning Objectives
Business Alignment
Align AI evaluation strategies with core business goals and KPIs for measurable impact.
Systematic Error Analysis
Develop systematic processes for identifying, classifying, and prioritizing LLM failure modes.
Automated Evaluation
Build and validate automated evaluation pipelines using code-based checks and LLM-as-judge evaluators.
Production Integration
Integrate evaluations into CI/CD lifecycle to create robust quality gates and enable safe, continuous improvement.
Architecture-Specific Strategies
Implement specialized evaluation techniques for RAG and Tool Use architectures.
Cost Optimization
Analyze and optimize cost-performance trade-offs through intelligent routing and targeted evaluations.
Course Overview
A practical, end-to-end framework for evaluating LLM applications. Build robust, reliable, and business-aligned AI systems.
Do you catch yourself asking these questions?
If any of these sound familiar, this course will give you the answers.
"How do I test applications when the outputs require subjective judgments?"
Most AI outputs are not objectively right or wrong. A response can be technically accurate but unhelpful, or helpful but slightly imprecise. Traditional unit tests do not work here.
Answered in Modules 3 and 4: You will build LLM-as-judge evaluators that score subjective quality with binary pass/fail assertions calibrated against a domain expert. Module 4 teaches you to measure judge-human alignment using confusion matrices and Cohen's kappa, so you can scientifically trust your automated judgments. The key insight: convert subjective criteria into specific, testable assertions. "Be helpful" becomes "response includes at least one specific action the user can take."
"If I change the prompt, how do I know I am not breaking something else?"
Every prompt change is a potential regression. A tweak that improves tone might degrade factual accuracy. Without a regression test, you are shipping blind.
Answered in Module 6: You will set up prompt regression testing in CI/CD. Every prompt change runs against a versioned test set. A GitHub Actions workflow compares old vs new scores, posts results to the PR, and blocks merge if any metric drops more than 5%. You will also learn stratified evaluation, which catches the "better on average, worse on edge cases" trap by breaking results down by query category.
"Where should I focus my engineering efforts? Do I need to test everything?"
Evaluating everything is as wasteful as evaluating nothing. A fluency eval on a model that already produces perfect grammar costs money and catches zero issues.
Answered in Modules 2 and 8: Module 2 teaches systematic error analysis: review 50-100 real traces, build a failure taxonomy, and prioritize by severity times frequency. You write evals for the failures that actually happen, not the ones you imagine. Module 8 teaches when NOT to write an eval: if the metric is already solved by the model, if the task changes faster than your eval, or if human review is cheaper. The decision framework: "What decision will this eval inform? If you cannot name the decision, do not write the eval."
"What if I have no data or customers? Where do I start?"
The cold start problem. You cannot do error analysis without traces. You cannot build evaluators without test cases. And you have neither.
Answered in Module 2: You will learn three synthetic data generation techniques: persona-based generation (simulate 5 user types), seed expansion (turn 10 hand-written examples into 100 variations), and failure-mode-targeted generation (use your taxonomy to generate test cases for each category). The code uses the Anthropic SDK to generate diverse, realistic test data before you have a single real user. Airbnb used this exact approach to bootstrap their search evaluation.
"What metrics should I track? What tools should I use?"
The metrics landscape is overwhelming: BLEU, ROUGE, BERTScore, RAGAS, G-Eval, CLIPScore. Most are irrelevant to your specific product.
Answered in Modules 1 and 5: Module 1 introduces the Three Gulfs framework for diagnosing which metrics matter. Module 5 goes deep on architecture-specific metrics: RAGAS (context precision, recall, faithfulness) for RAG systems, tool selection accuracy for agents, and context retention for multi-turn conversations. The tools: LangFuse for tracing and scoring, Arize Phoenix for local embedding visualization, and Promptfoo for development-time testing. The course is framework-agnostic and works with Claude, GPT, Gemini, or any model.
"Can I automate testing and evaluation? If so, how do I trust it?"
Automating evals with an LLM judge sounds circular: using AI to evaluate AI. How do you know the judge is not making the same mistakes as the system it evaluates?
Answered in Modules 3, 4, and 7: Module 3 teaches you to build both deterministic evaluators (code-based, 100% reliable, zero cost) and LLM judges (semantic, flexible, needs calibration). Module 4 teaches calibration: run the judge and a human expert on the same 30 traces, build a confusion matrix, and measure agreement with Cohen's kappa. Target: kappa above 0.7. Module 7 closes the loop with a data flywheel: human reviewers catch what judges miss, those corrections improve the golden dataset, and the judges get better over time. After setup, maintaining the system takes about 30 minutes per week.
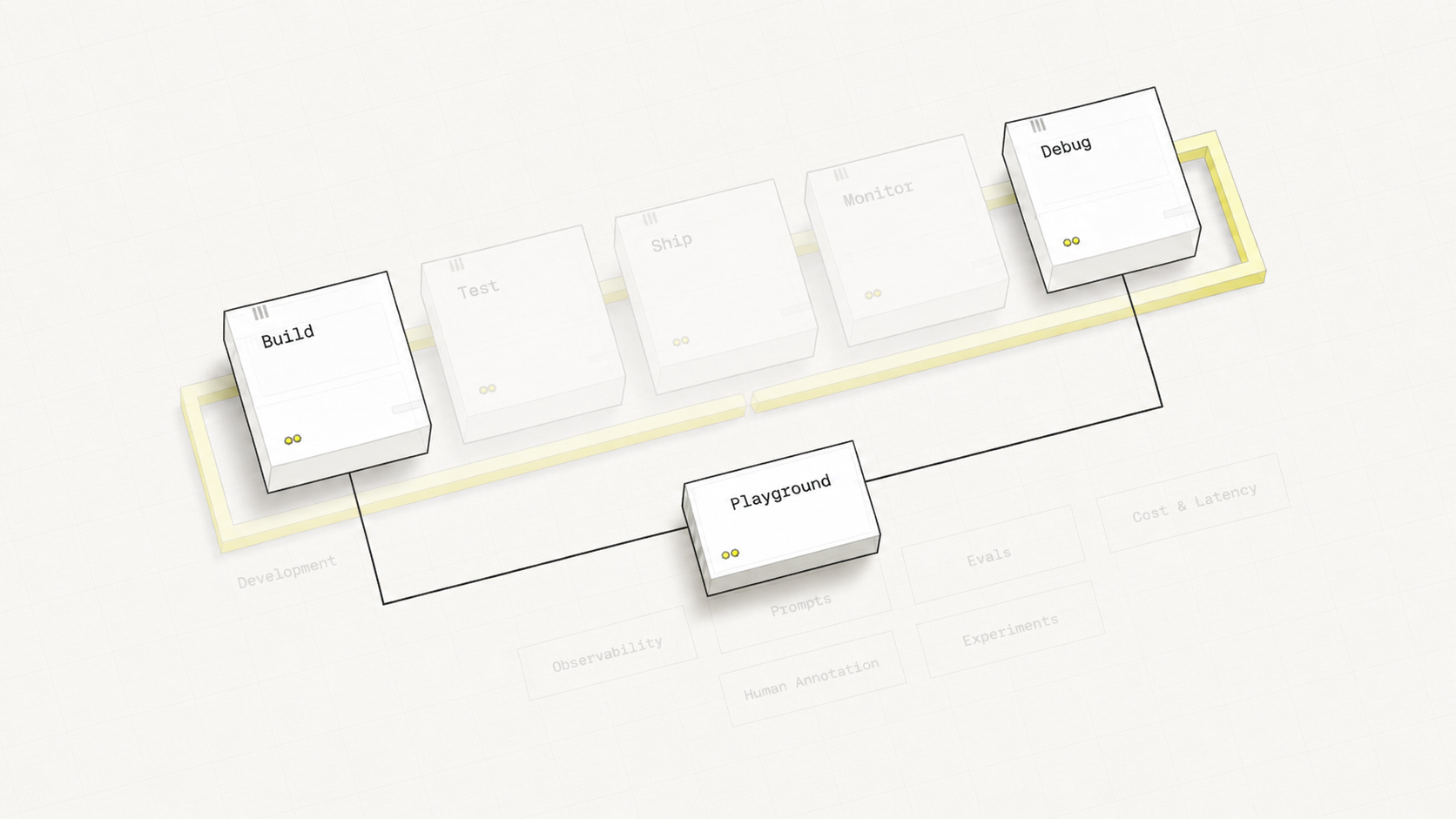
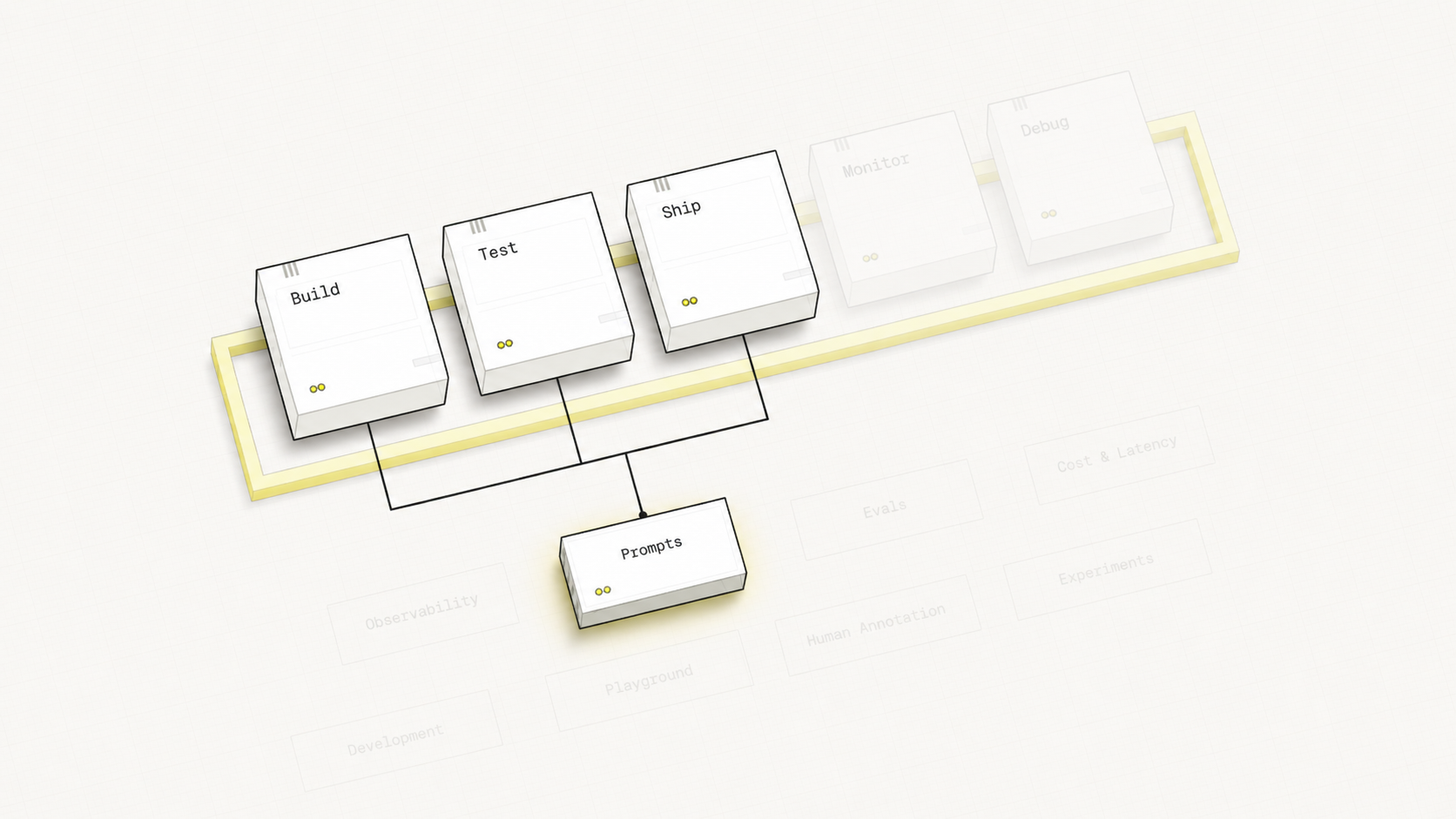
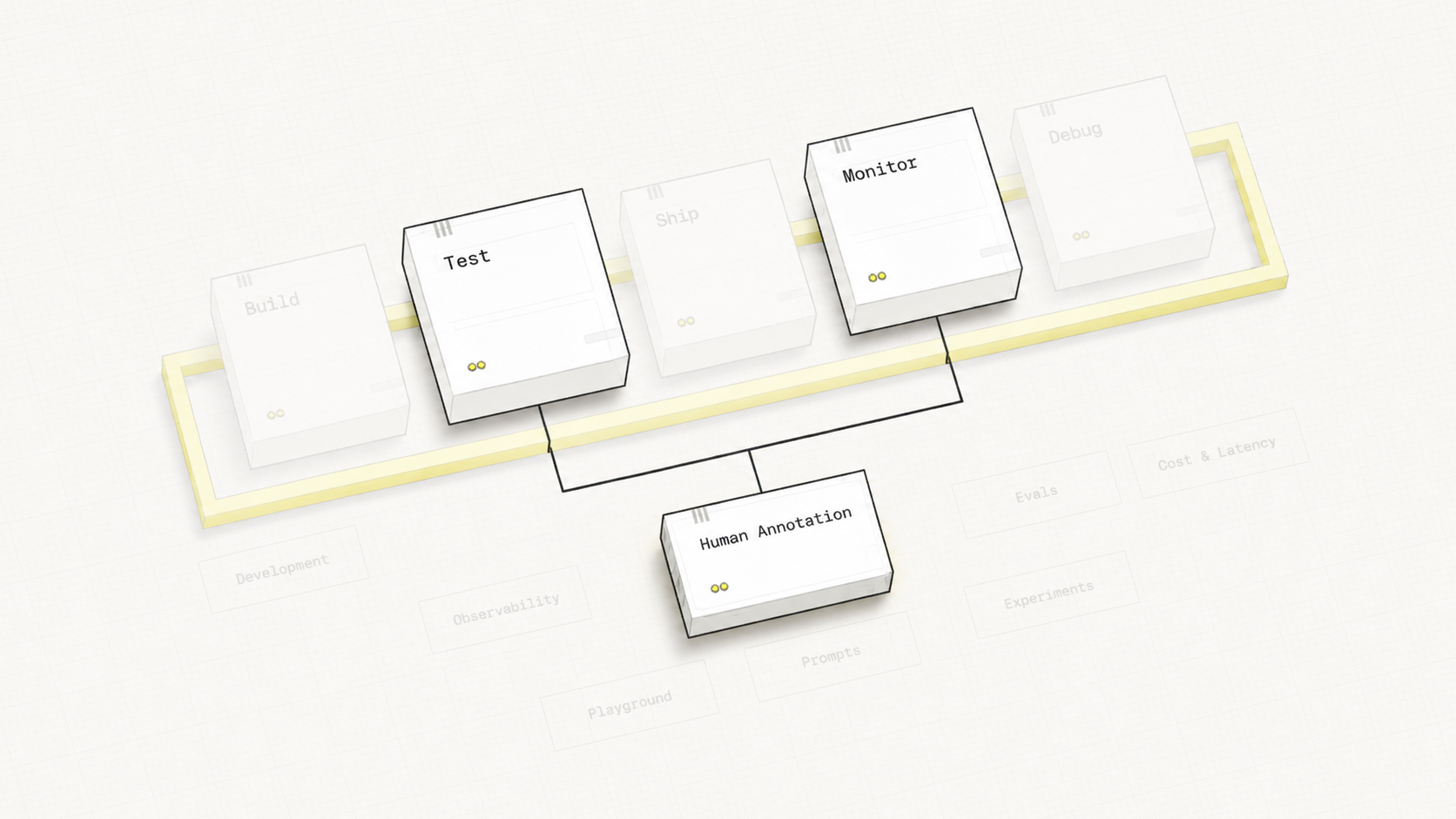
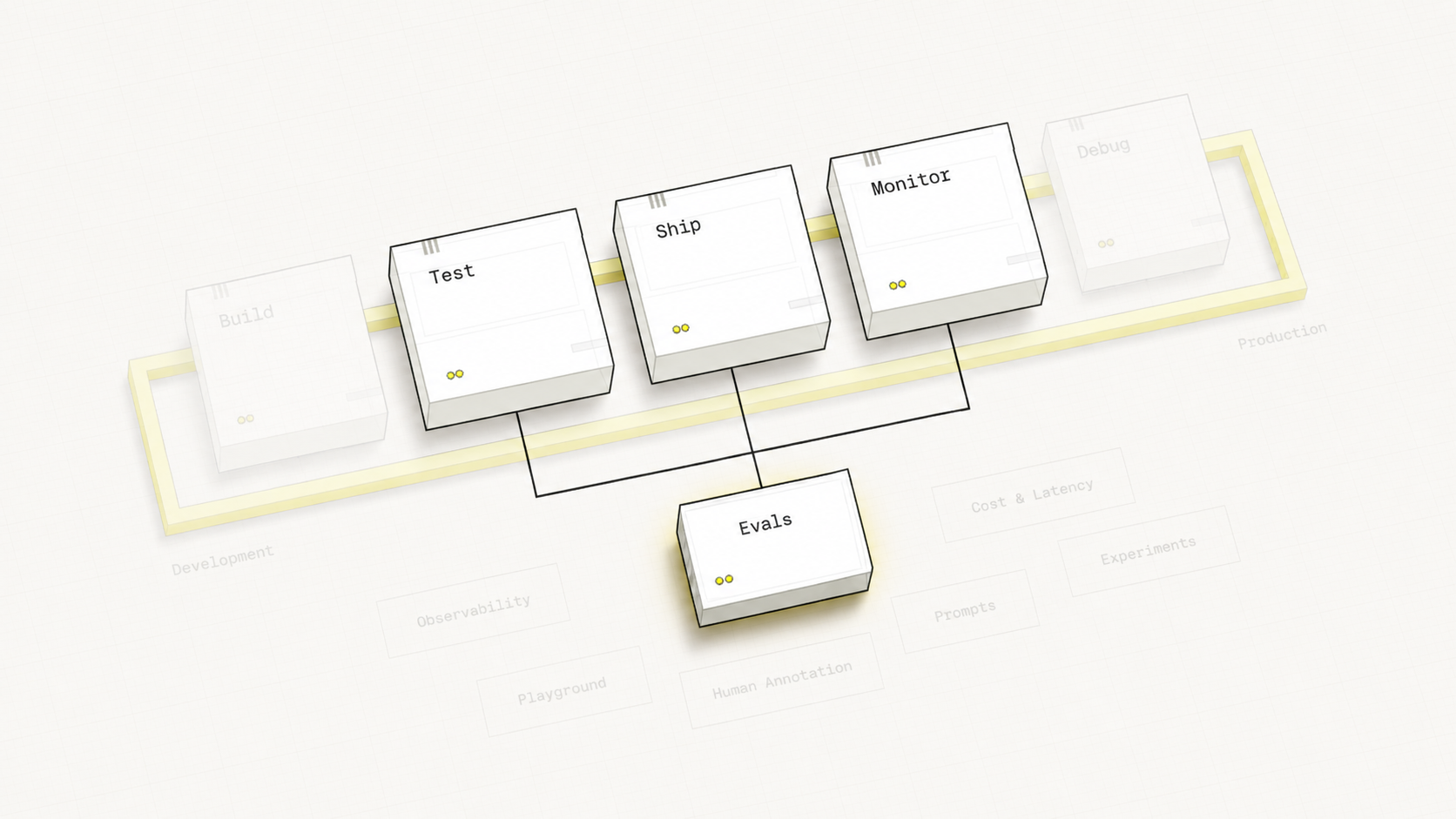
Your Learning Journey
Foundations
Analysis
Evaluators
Production
Capstone
Hover over each stage to discover its components
What Evals Actually Are
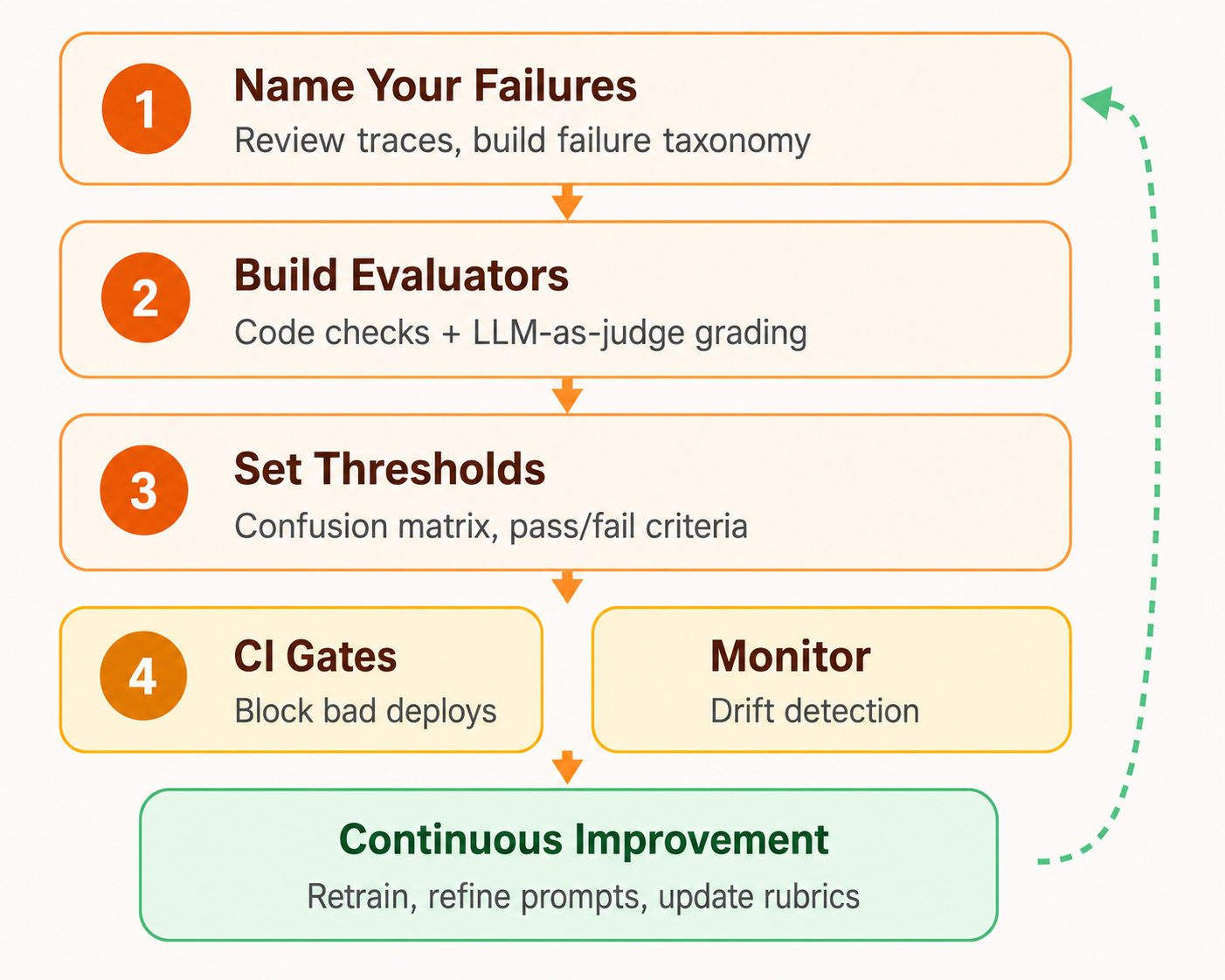
Evals are a structured process for measuring whether AI products behave as intended. They are distinct from unit tests, benchmarks, or PRDs. Instead, they connect messy reality to a repeatable improvement process through a 5-step loop:
Examine real conversations
Review 40-100 system traces to identify the first upstream error per conversation
Document observations
Write specific, product-aware notes (e.g., 'Should have handed off to a human' not 'janky')
Group into failure modes
Organize into 4-7 actionable categories with a domain expert maintaining consistency
Build automated checks
Pure code for simple checks (format, tool calls), LLM-as-judge only for semantic decisions
Operationalize and monitor
Run in CI and production sampling, track trends by category, prioritize by business risk
The M.A.G.I. Framework
The course is built around the M.A.G.I. framework, a production-tested approach to AI evaluation with four pillars:
Metrics
QAG, G-Eval, Contextual Precision/Recall, Tool Correctness. Select 5 or fewer metrics per use case.
Automation
CI/CD integration with offline and online scoring. Target under 5 minutes per eval execution.
Governance
Metric ownership, quarterly reviews, golden-dataset versioning. Keep your eval framework trustworthy.
Improvement
Full-funnel tracing, threshold tuning, continuous feedback loops. Data-driven refinement cycles.
Real-World Case Studies
Learn from production failures that drove the creation of this evaluation framework:
The Coffee Machine Reimbursement Trap
RAG FailuresHigh RiskA retrieval system fetched permissive policy language while omitting exclusion details. High faithfulness with wrong context is dangerous.
Faithfulness 95% | Contextual Recall 45% | Contextual Precision 60%
The Outdated PTO Policy Nightmare
Temporal & Data IssuesBusiness CriticalUsers received guidance based on obsolete policies despite current information existing in the knowledge base under poor metadata.
Temporal Accuracy 25% | Contextual Precision 30% | 23 User Complaints
Agent Tool Hallucination Crisis
Agent ReliabilitySystem CriticalProduction agents generated calls to non-existent tools or malformed parameters, triggering system failures and emergency rollback.
Tool Correctness 70% | Task Completion 45% | System Uptime 82%
Free Resources on EvalMaster
What Evals Actually Are
The 5-step loop methodology
M.A.G.I. Framework
Measure, Automate, Govern, Improve
Architecture Patterns
8 patterns from Simple RAG to Multi-Agent
Metric Catalog
16 eval metrics with benchmarks
Case Studies
Production failure analysis
LangGraph Agents
Agent orchestration patterns
Implementation Guide
Step-by-step setup
Integrations
LangChain, LlamaIndex, Langfuse
Course Modules
8 self-paced modules, each with a hands-on assignment, followed by a capstone project. Learn at your own speed.
Module 1
Foundations & Lifecycle
Anchor on business goals and set up the foundational plumbing for evaluation.
- How evals reduce risk and drive impact (aligning to KPIs like conversions, CSAT, cost)
- LLM-specific pitfalls: stochasticity, context dependence, tool/RAG failure modes
- The evaluation lifecycle: dev to pre-prod gates to prod monitoring to continuous improvement
- Minimal instrumentation: traces, spans, session IDs, prompt/tool logs
Deliverable: Baseline PRD with metrics map, tracing enabled on a sample application, and a one-page evals plan
Module 2
Systematic Error Analysis
You can't measure what you haven't named. Learn to turn raw failures into an actionable taxonomy.
- Sampling strategies for error analysis (real traces vs. synthetic data)
- Open-coding techniques to identify root errors and axial coding to group them
- Basic quantitative analysis of qualitative data (pivot counts, severity, risk ranking)
- Common anti-patterns: vague labels, committee thrash, overfitting
Deliverable: Error log from labeling 40-100 traces, a v1 failure taxonomy, and a prioritized Top 5 Failure Modes document
Module 3
Evaluators That Stick
Convert your taxonomy into automated checks that can run at scale.
- Designing deterministic checks: schema/JSON validity, required fields, tool-call presence, latency/cost thresholds
- Designing semantic checks (LLM-as-judge) for judgment calls ensuring binary outputs
- Best practices for test dataset organization and versioning
Deliverable: An evaluation runner (CLI, notebook, or CI job) that executes both code-based checks and 1-2 LLM judges against a test dataset
Module 4
Alignment & Collaboration
Ensure your automated judges are trustworthy and aligned with human judgment.
- Inter-annotator agreement (IAA) basics to de-bias rubrics
- Using a confusion matrix over raw accuracy to understand and reduce false positives and false negatives
- Implementing a simple governance loop for proposing, reviewing, and accepting changes to evaluators
Deliverable: A confusion matrix comparing an LLM judge to human labels, an alignment write-up, and a change-control checklist
Module 5
Architecture-Specific Strategies
Apply targeted evaluation techniques to the architectures that matter most.
- RAG metrics: Contextual Precision, Recall, Faithfulness, chunk-level attribution
- Tool Use testing: correct tool selection, parameter accuracy, retry handling
- Multi-turn continuity: session-level coherence, state tracking across turns
- Designing architecture-aware test suites with edge cases
Deliverable: A targeted test suite for one architecture pattern (RAG or Tool Use) with pass/fail thresholds
Module 6
Production Monitoring
Move evaluations from notebooks into CI/CD and live production monitoring.
- CI/CD integration: eval gates in GitHub Actions, pre-merge quality checks
- Safety guardrails: PII detection, toxicity filters, policy compliance
- Production tracking: real-time dashboards, alerting on metric drift
- Canary deployments and shadow scoring for safe rollouts
Deliverable: A functioning CI gate that blocks merges on eval failure, plus a production sampling config
Module 7
Human Review Workflows
Design efficient human-in-the-loop processes that scale.
- Strategic sampling: when and what to send to human reviewers
- Reviewer UX: annotation interfaces, rubric design, calibration sessions
- Feedback loops: routing human judgments back into golden datasets and judge tuning
- Measuring reviewer agreement and handling disagreements
Deliverable: A human review workflow spec with sampling strategy, rubric, and feedback integration plan
Module 8
Cost Optimization
Ship quality without burning budget. Optimize the cost-performance frontier.
- Value mapping: which evaluations deliver the most signal per dollar
- Smart routing: model cascades, cached responses, selective evaluation
- Performance trade-offs: latency vs. quality vs. cost Pareto analysis
- Building a cost model and projecting savings at scale
Deliverable: A cost optimization plan with measured baselines and projected savings
Capstone
Capstone Project
Select one real-world agent workflow and build a production-grade evaluation program:
- Refined failure taxonomy with data-backed prioritization
- Automated pipeline with 3+ deterministic checks and 2+ LLM judges
- Confusion matrix and performance thresholds
- Architecture-specific test suite
- Functioning CI gate and production dashboard
- Documented cost optimization plan
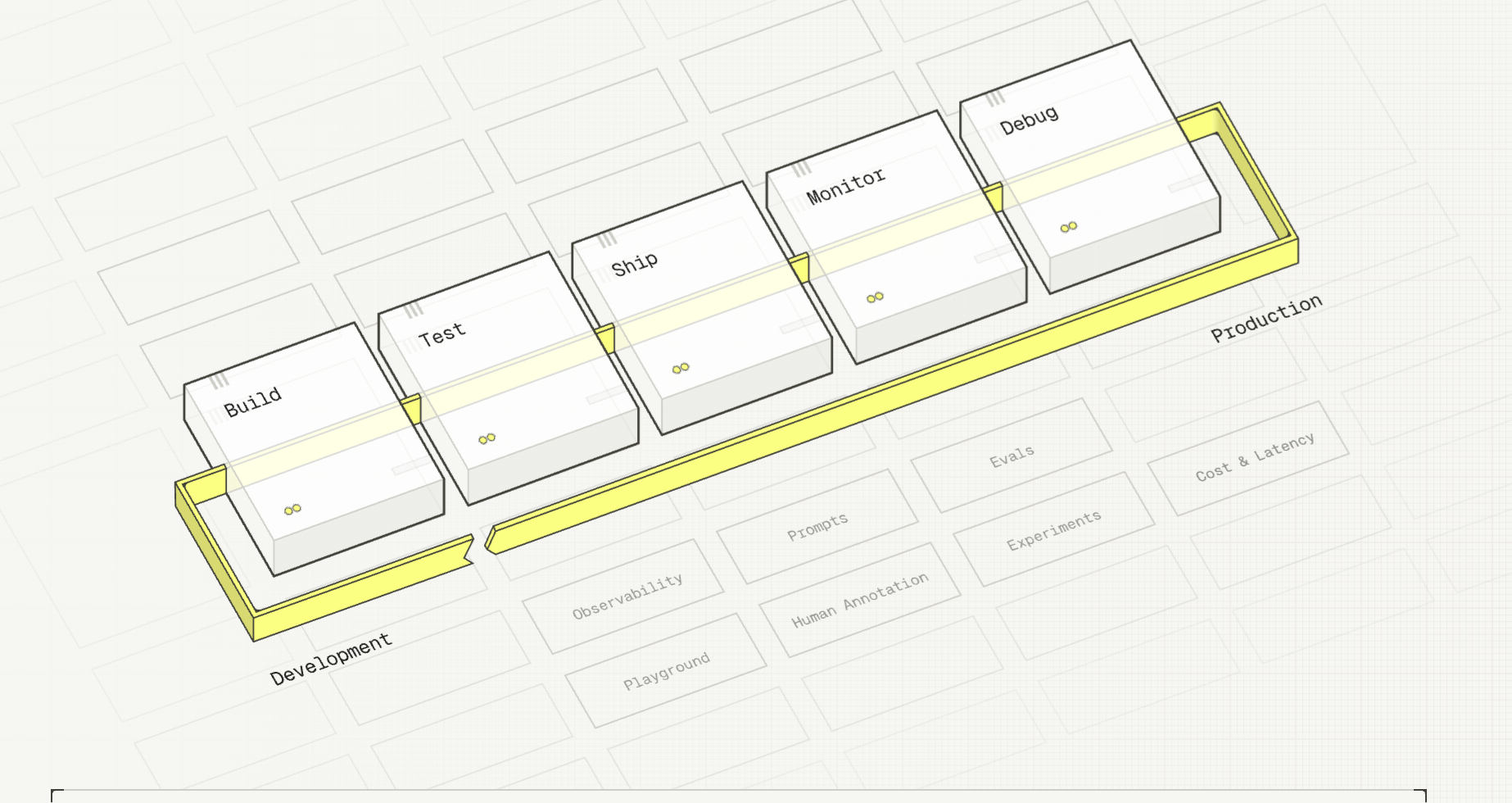
Build, test, ship, monitor -- repeat.
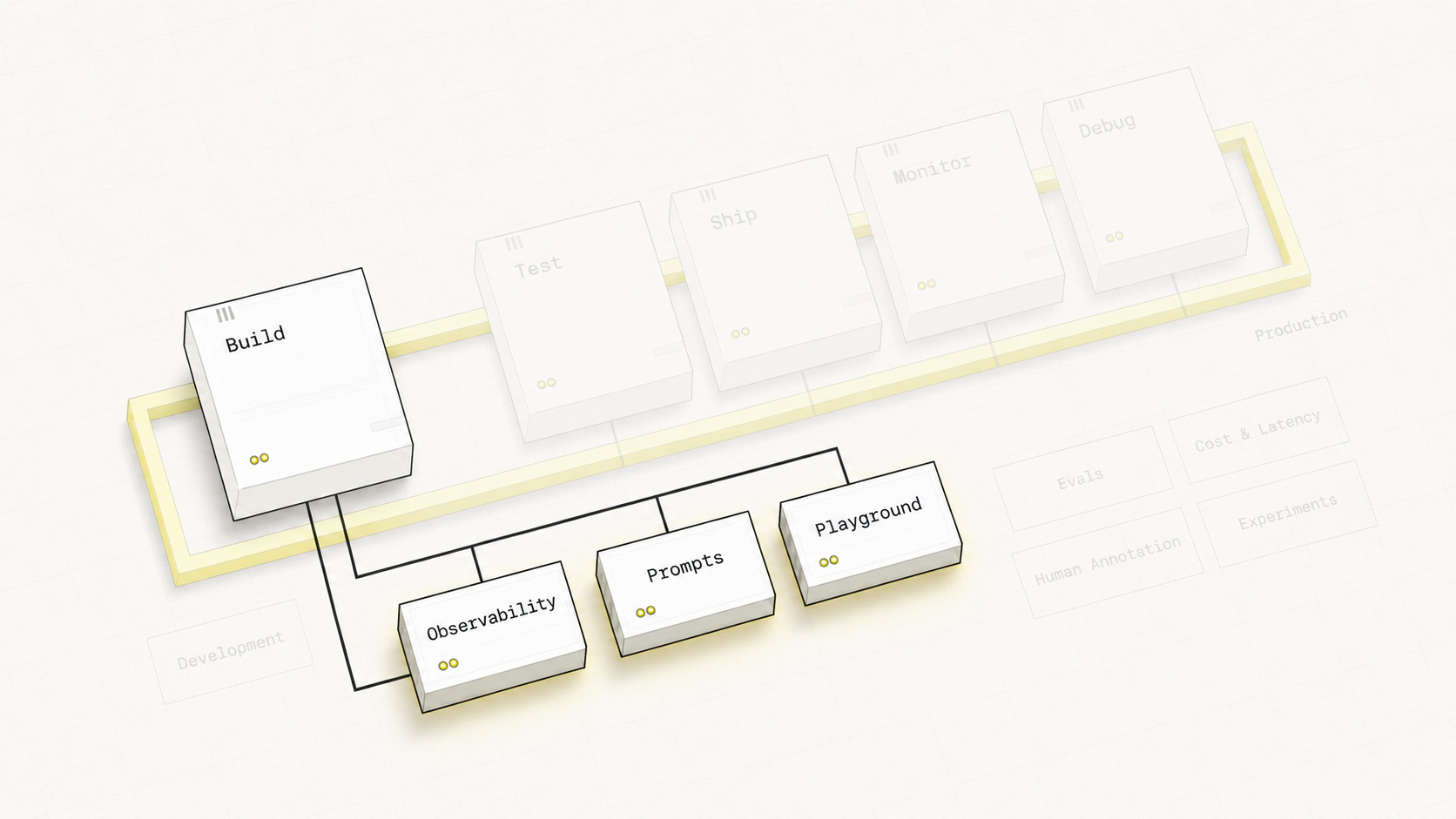
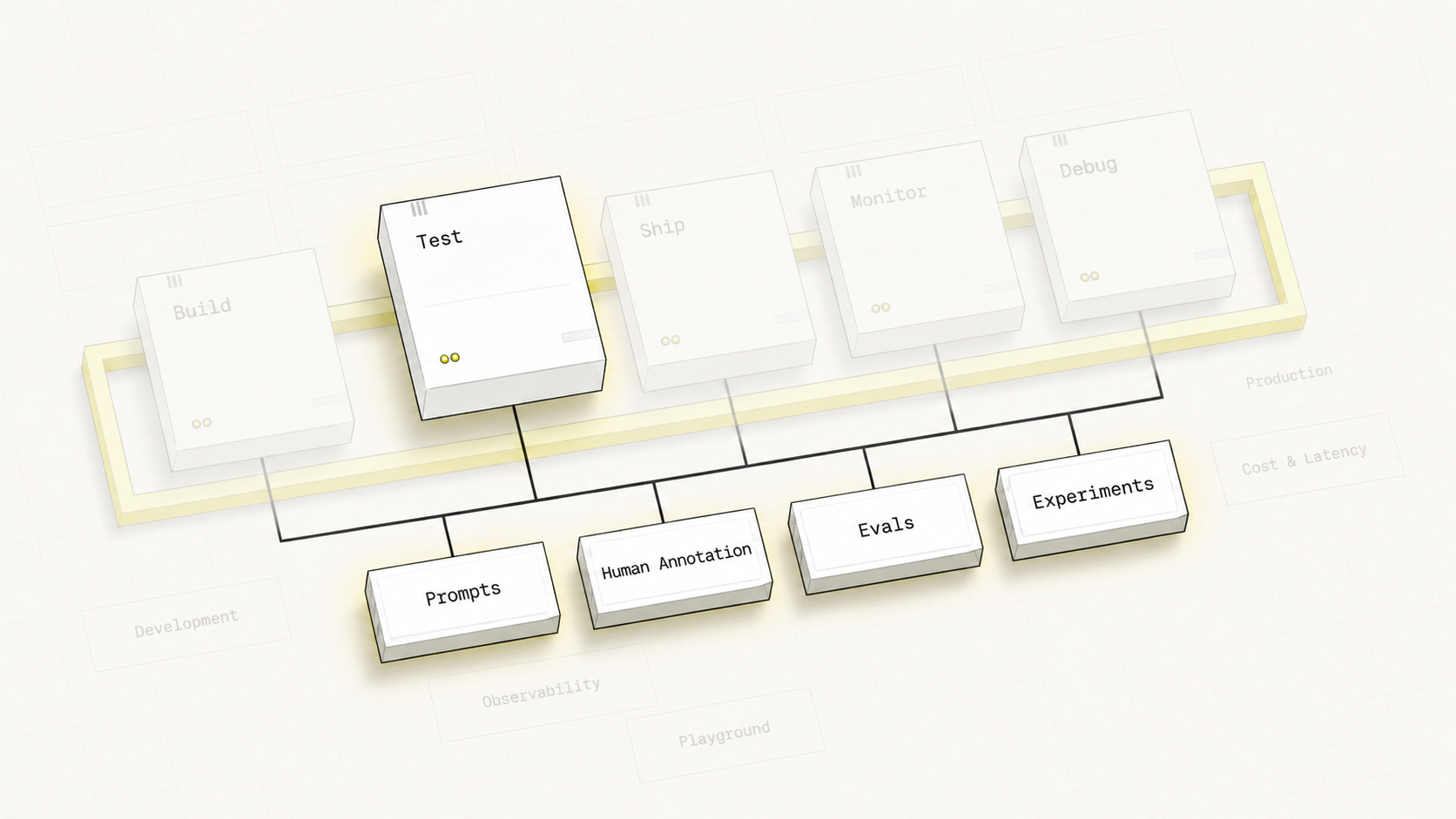
Hover over any pipeline stage or feature label to explore the connections between them.
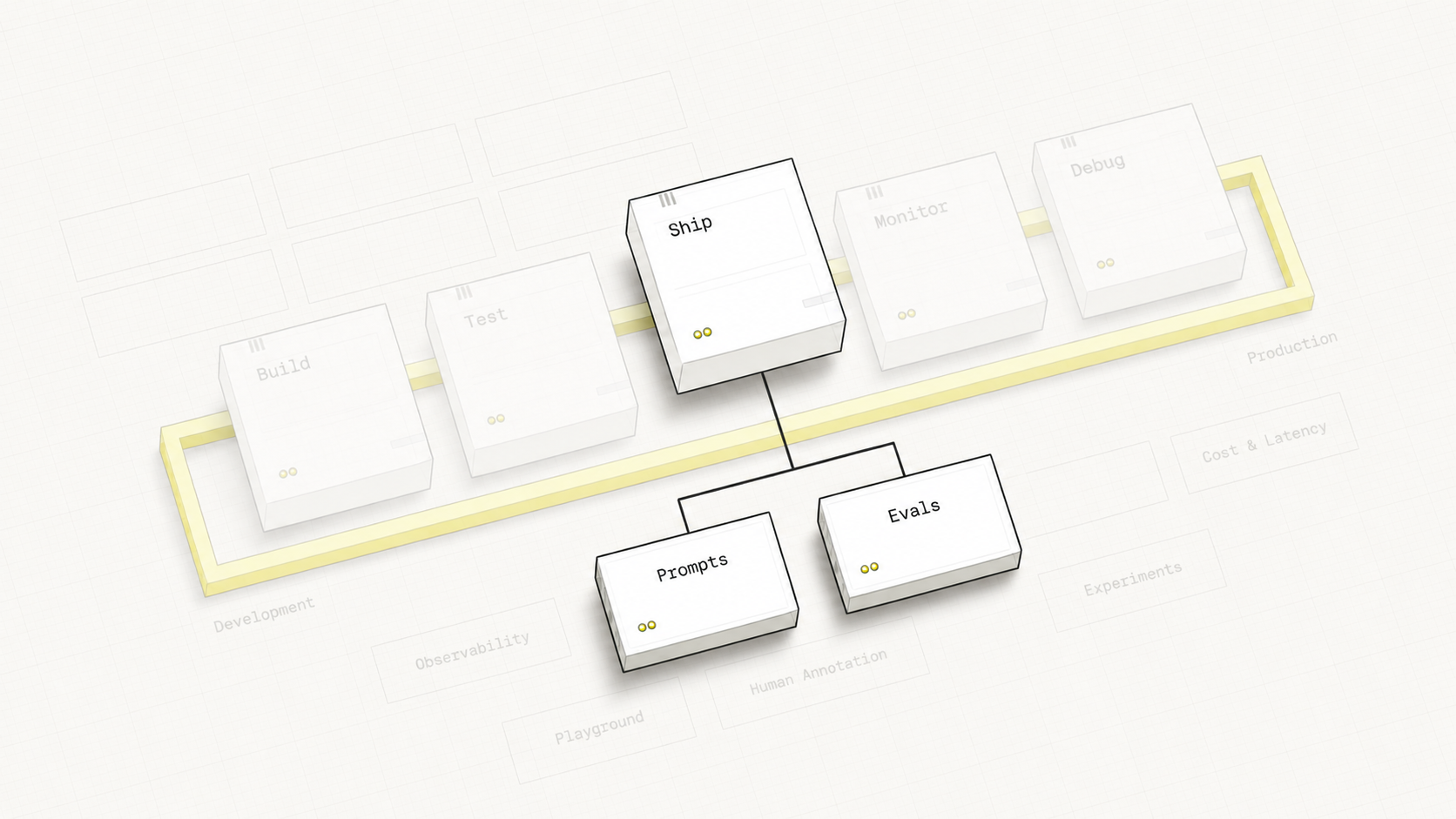
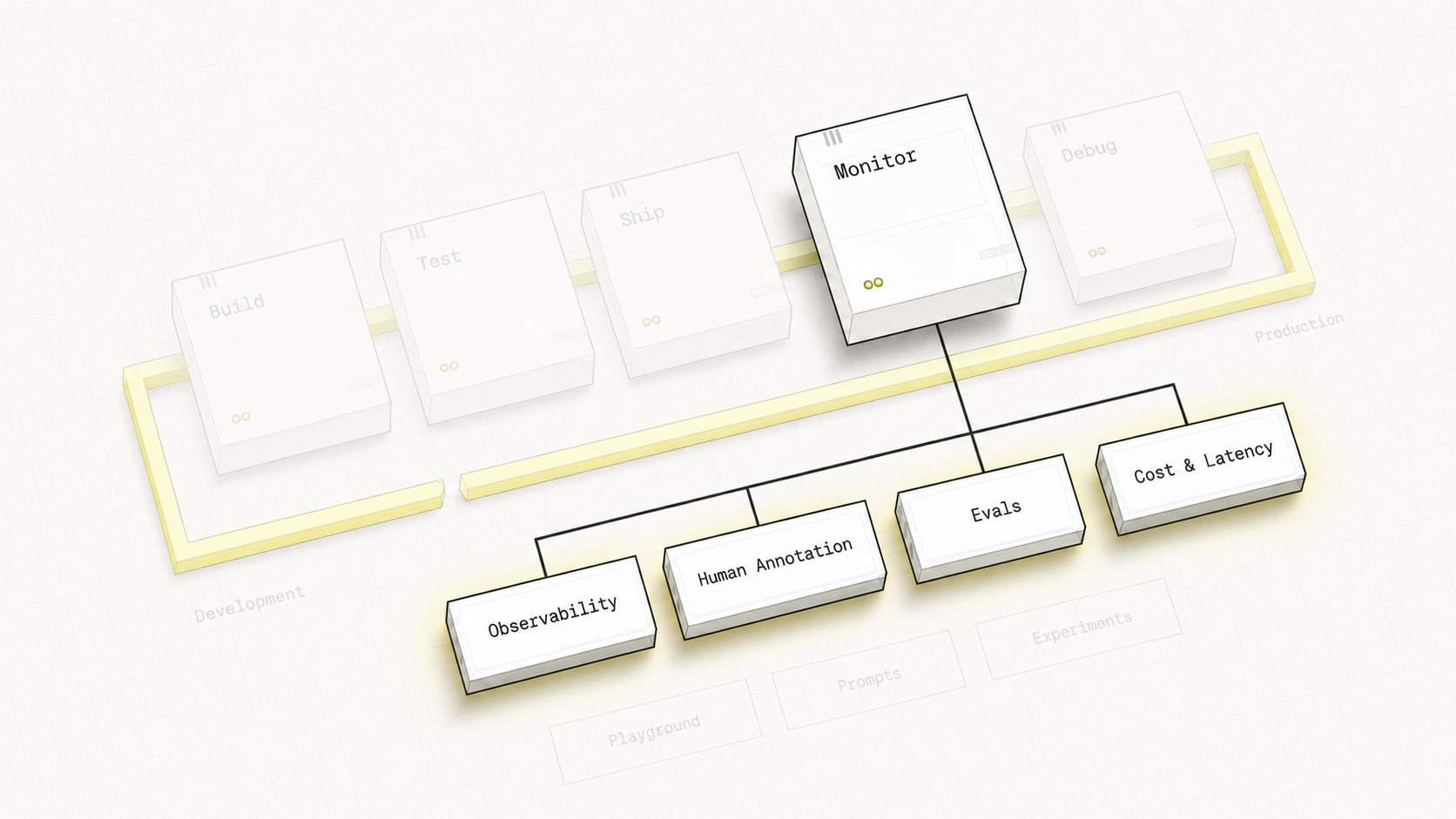
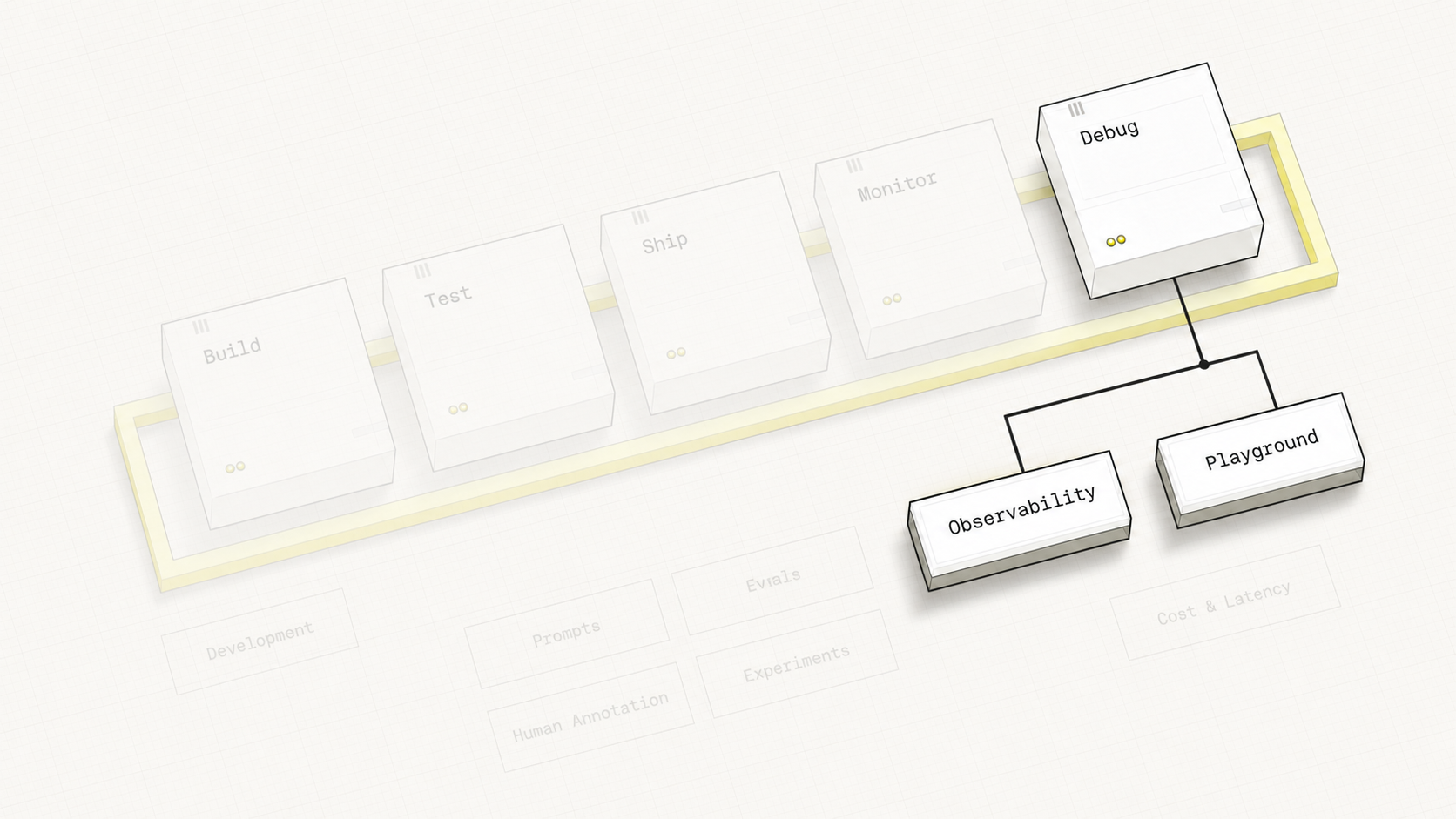
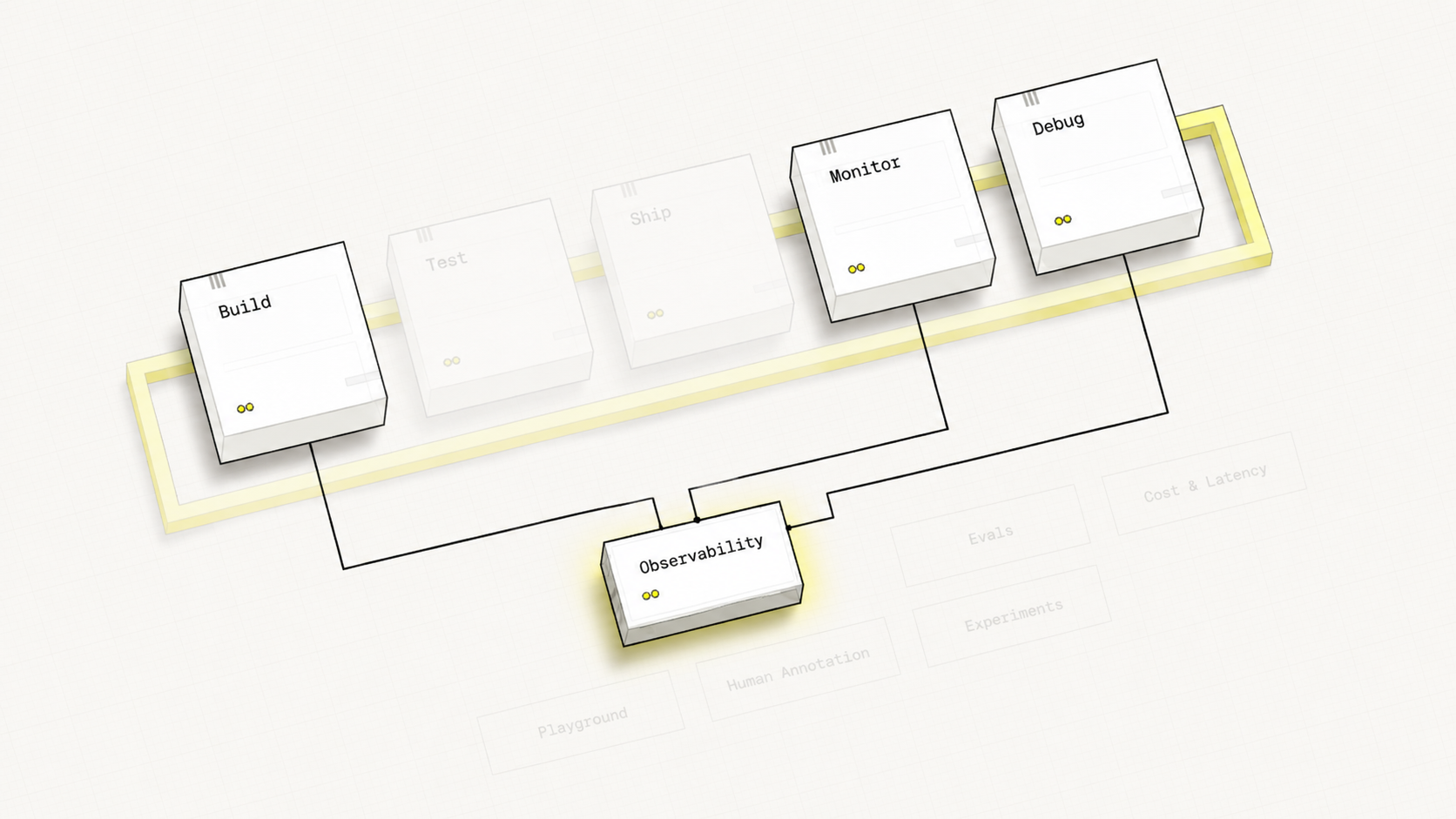
Capstone Overview
Theory, requirements, rubric, timeline, and submission guidelines. Start here to understand what you are building.
View Overview →
Capstone Implementation
Hands-on build with starter kit, LangFuse + Arize Phoenix, rental property walkthrough, interactive exercises, and production code.
Start Building →
Ready to master AI evals?
Start with Module 1 and work through the full course at your own pace. Earn a certificate on completion.
Start Course